In this lesson you'll learn what the DOM (Document Object Model) is
and why it's important. You might not use the DOM too much while
learning HTML but it's still important to understand what it is
and how it works so you can create valid, efficient web documents.
We code our pages using HTML tags and attributes.
When that code is loaded into a browser, the browser
interprets all of our code and tries to render a
DOM. DOM is short for Document Object Model.
In other words, a DOM is a model of all the objects
in your document.
The objects represent the different
elements, attributes, and content of your page. For
example, elements like <html> and <img> are
represented by Element Objects. Attributes like
src and href are represented by
Attribute Objects.
These objects contain special properties and methods
you would eventually use to manipulate the various items on
the page using a language like JavaScript. The W3C defined the HTML
DOM standard that determines what objects exist and what
properties and methods they have, which helps to make things
more consistent: you can actually program an HTML DOM using
many different languages and technologies! Many of the components
on this page are actually created using JavaScript code that adds objects
to the DOM. For example, the headers and footers on all of these
tutorial pages are created by using JavaScript to add objects to the
DOM for the coures name heading, page title heading, copyright information
container, etc.
You can also use the DOM objects when you want to style your
HTML pages with CSS. For example, in my tutorial pages, I have
CSS code that styles all the list item objects with different
bullet styles and all the navigation objects with specific
background colours.
When coding HTML, it's important to understand the DOM and
The DOM Tree so that you can create efficient
HTML code that is valid and easy to maintain.
The DOM Tree
The DOM Tree is a hierarchical structure that displays
the various nodes in the DOM.
Nodes are the different types of objects in the DOM, and they're
depicted with boxes (or other box-like shapes).
For example, if we had the following HTML code:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Lorum Ipsum</title>
</head>
<body>
<h1>A Web Page</h1>
<div>
<h2>Lorum Ipsum</h2>
<img src="images/image.png">
<div class="decoration">Lorem ipsum dolor sit amet, consectetur
adipiscing elit. Donec bibendum metus at mi tincidunt, a
pellentesque magna laoreet. Duis quis imperdiet enim. Sed
nec felis ex.</div>
</div>
</body>
</html>
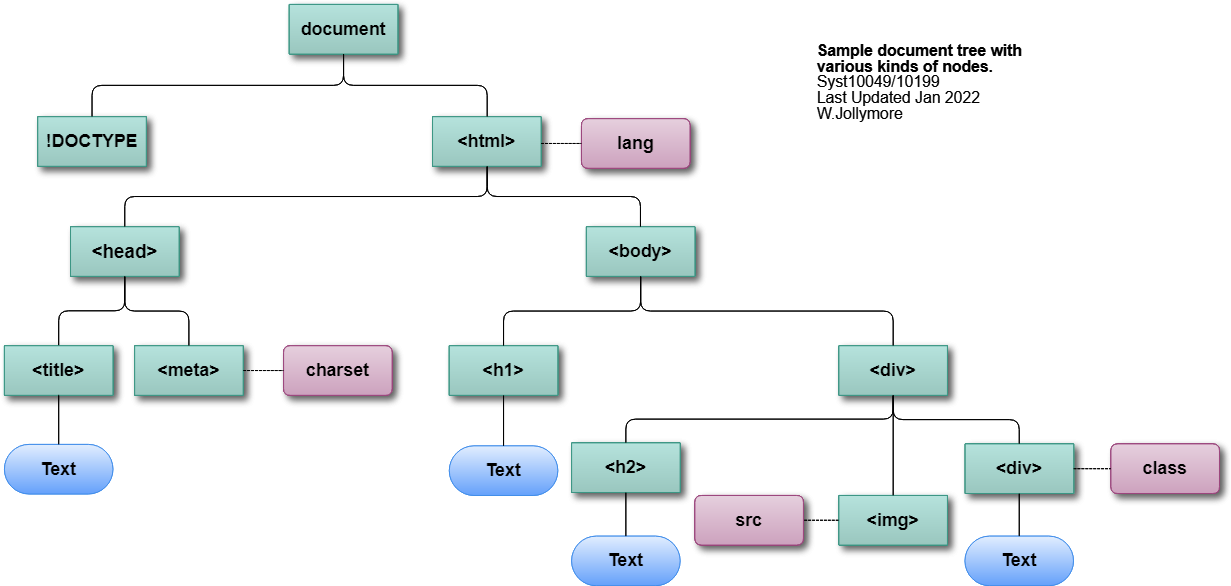
We would then represent that code by the following DOM tree:
Sample DOM Tree
There are three kinds of nodes in a DOM tree for an HTML document:
Element Nodes model the actual HTML elements in the document.
Element nodes are joined to each other in the DOM tree with solid lines that
connnect to or from the top or bottom of the node. The labels on the
element nodes may or may not have the pointy brackes. For example, a node for
the <html> element might have the label "<html>", "html", or "HTML".
Attribute Nodes model the various attributes in the different
HTML elements. Attribute nodes are joined to element nodes with dashed or
dotted lines (although sometimes developers will use a solid line instead,
so the placement of the line connections is very important)
connecting the side of the attribute to the side of the element
the attribute belongs to. The label of attribute nodes is simply the name
of the attribute. There is no need to include the value of the attribute.
Text Nodes model the text content inside the different HTML
elements. Text nodes are joined to the element nodes they belong to with a
solid line that connects the top of the text node to the bottom of the element
node. All text nodes have the label "Text". There is no need (and in fact
in many cases it would be cumbersome) to display the actual text.
DOM Tree: Node types
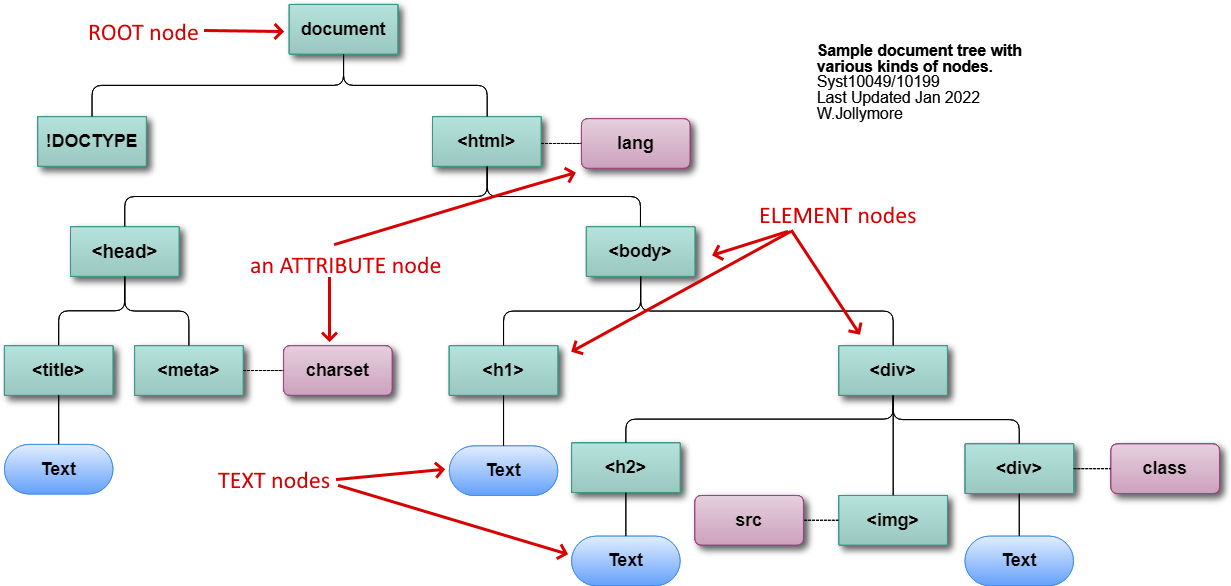
HTML elements inside
the document, such as the <hmtl> or <div> elements, are element
nodes. For example, in the code up above, you can see there are element nodes
in the DOM tree for the <html>, <head>, <meta>, <title>,
<body>, <h1>, <h2>, <img>, and the <div> elements.
All elements inside an HTML document should have corresponding nodes in
the DOM tree. Note that an element node appears
in the DOM tree whether it has both opening and closing tags, or only the opening
tag.
Attributes of HTML elements, such as href or src, are represented
as attribute nodes. Note that an attribute node appears
in the DOM tree even if it's not assigned an attribute value. In our
coded example and the corresponding DOM tree image, you can see there are
attribute nodes for the HTML element (lang), META element (charset), IMG
element (src), and the innermost DIV element (class).
Some elements contain text (such as the text inside the <title></title>
element tags), and these are represented as text nodes.
Note that not all element nodes will contain text nodes. For example, an <img>
element node will have no text node. Note that even though attributes
are assigned values in your HTML code, we don't represent those values
as text nodes. Text nodes only show the actual text that is part of the
document content. In our example, you can see the text nodes coming out
of the TITLE element, H1 and H2 elements, and the innermost DIV element.
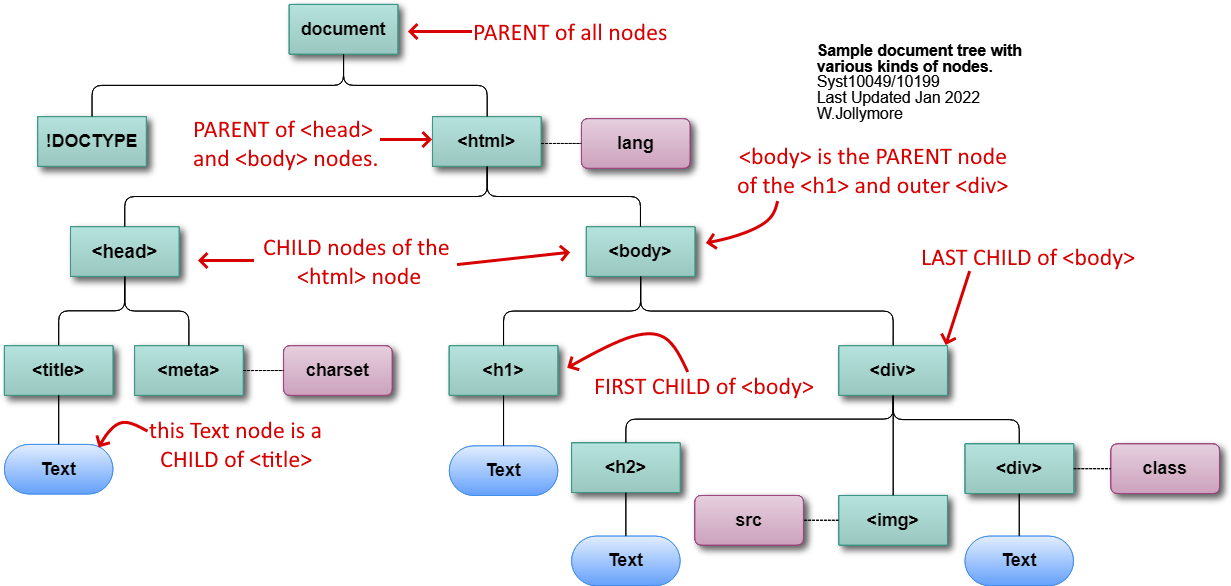
The Document Node or Root Node
The entire HTML document is modeled in the DOM by the
document node, which is always at the very
top of the DOM tree.
The document node is the root node of the document tree:
it's the parent of all of the other nodes.
Note that this node does not represent the <!doctype> element, it
just happens to have a similar name.
Parent and Child Element Nodes
DOM nodes (specifically, element nodes) are often (but not always)
parent nodes, meaning that they
have child nodes coming out of them. Child nodes
can be other element nodes, or text nodes. For
example, in our DOM tree example, the <div> that is
coded immediately under the <h1> in the source code
is the parent of the
IMG node in the DOM tree. In fact, that outermost DIV node has
three children:
the H2 node, IMG node, and the innermost DIV node.
DOM Tree: Parent/Child Nodes
Child nodes are always joined to their parent node with a solid line that
connects the top of the child node's box to the bottom of the parent
node's box. Do not connect element nodes on the sides: that is reserved for
attribute nodes, so if a DOM tree diagram is not in colour, it will be
difficult to tell which nodes are elements and which nodes are attributes.
All element nodes, except for the root node, have exactly one parent node.
The root node is the only node that has no parent. Any node in the
tree can have one or more child nodes: there is no limit on the number
of child nodes a node can have. In the actual HTML code, parent/child
node relationships occur when one element node is nested inside another,
or when an element contains text content: In our example above,
there is text inside the <title> element ("Lorum Ipsum"). In the
DOM tree, you can see there is a text node that is a child of the TITLE
node: that text node represents the text content "Lorum Ipsum" of the <title>
element.
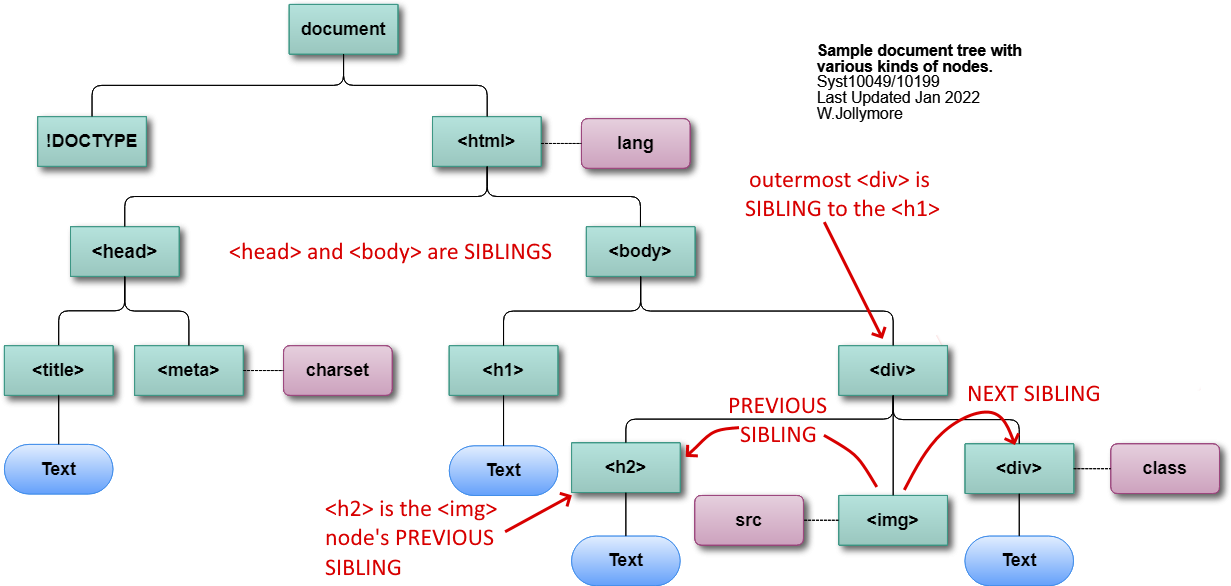
Child nodes that share the same parent node are called
siblings. For example, the IMG node, inner DIV
node, and H2 node are all siblings of each other. In fact, we can
get more specific and refer to the H1 node as the first child
of the outer DIV node. Furthermore, we can refer to the innermost
DIV as the last child of the outermost
DIV node. Additionally, when looking at the IMG node, the
H1 node is the previous sibling and the lower DIV is the
next sibling. These terms are important because
when you want to style nodes with CSS or manipulate them with JavaScript,
you will often need to refer to a node's parent, children, or siblings.
For example, on my notes pages with many sections, there's always a
small navigation bar at the end of each section that allows you to
easily jump to another section of the same document. I created these
in JavScript by adding a <nav> element with the appropriate links, and
then adding this <nav> element as the "last child" of each
<article> element that defines each section.
DOM Tree: Sibling Nodes
Summary of Nodes
root node: the node on the very top of the
document tree, usually called the document node.
parent node: a node that has children; represents
an element that has at least one other element or text
nested inside it.
child node: a node that has a parent; represents an
element or text that is nested inside another element.
sibling node: two or more nodes that share the same
parent are sibling nodes; a sibling node represents an element
that is nested inside another element along with other
elements.
first child node: the very first child node inside
a parent node; represents the very first element defined inside
another element.
last child node: the very last child node inside
a parent node; represents the very last element defined inside
another element.
previous sibling node: the node before another node
at the same level in the document tree, where both nodes share
the same parent; represents an element that is defined before
another element, where both elements are nested inside a parent
element.
next sibling node: the node after another node
at the same level in the document tree, where both nodes
share the same parent; represents an element that is defined
after another element, where both elements are nested inside a
parent element.
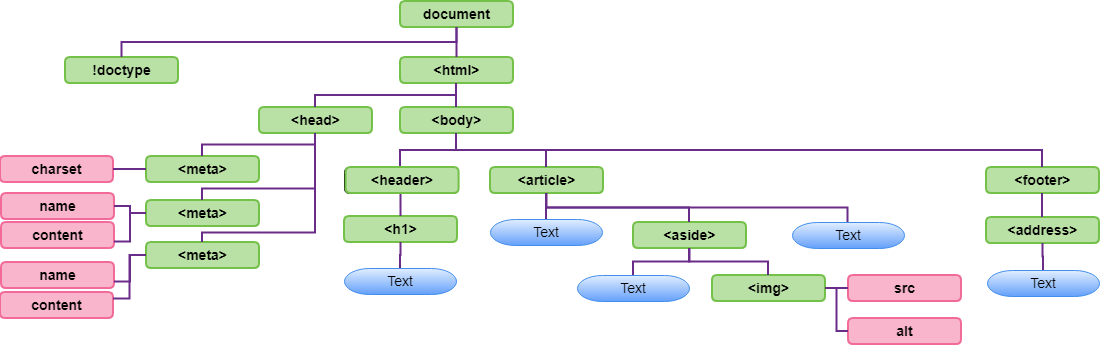
Exercise
For practice, see if you can use the diagram of this DOM Tree
to answer the questions below:
DOM Tree Exercise
How many children does the BODY node have? What are they?
How many children does the HEADER have?
What is the ARTICLE node's first child? What is the ARTICLE
node's last child?
What is the ARTICLE node's previous sibling? What is the
ARTICLE node's next sibling?
What is the META tags' parent?
What does the DOM do?
The DOM allows you to edit, add, delete, and access
individual document elements/tags, attributes, and their contents. The
most common means of doing this is by using JavaScript.
The DOM also allows you to create complex styling rules on
page elements using CSS. For example, you could specify that
the first list item in an unordered list have different styling
than all the other list items.
The DOM defines the various properties and objects that represent the standard
HTML elements you use to build the structure and content of a web page;
it also defines a set of methods you can use to access and manipulate
those properties and objects.
The DOM doesn't have to be accessed via JavaScript. Several other languages
can be used to access DOM objects, properties, and methods, such as Python,
Perl, PHP, and C++.
Exercise
Choose a simple web page (you could use
this page
if you have trouble finding one). Sketch out the DOM tree
for that page. You can view the text version of the DOM tree
by loading it in Chrome or Firefox and pressing Ctrl-Shift-I
("I" is short for "Inspect").