In order to create web sites and web applications, it's important
to understand how web applications work and how the Internet works.
The internet is a huge entitiy - a network of computers all over the world,
or a network of networks. The primary architecture of these networks is
the client-server network. This network architecture allows us to connect
our own individual machines to the millions and billions of machines
that make up the networks of the Internet.
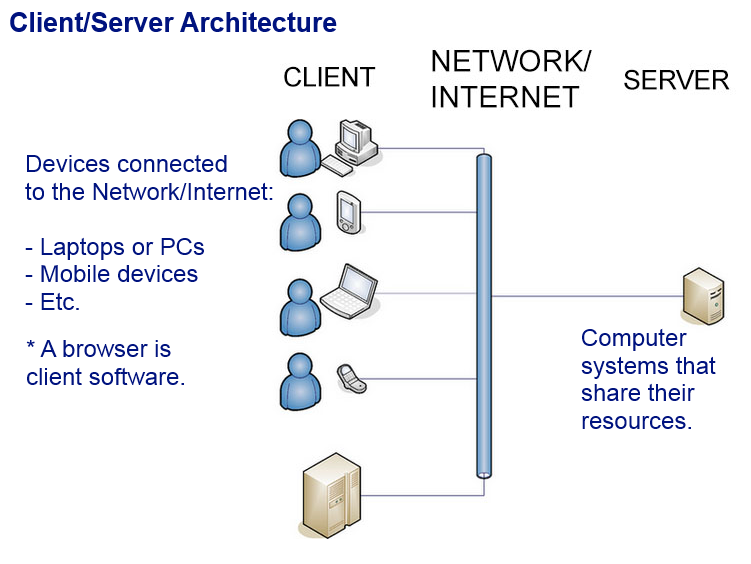
What is Client-Server?
When people refer to a client-server model, or client-server architecture,
they're referring to a design of networked machines with the main files,
programs, and services on a single computer called a server. Those
resources can be shared among other machines on the network, which
are called clients. The Internet is an example of client-server
architecture: Many resources are stored on servers, and we can all use
our own client machines to access those resources. The Internet is a huge,
complex map of clients and servers, all connected together, allowing the
world to share an infinite supply of electronic resources.
Client-Server Example: Internet
A server
is also the software that manages the server's connections and access, and
"serves" up requests for resources that are made by client machines. The machine
that the server software resides on can be any computer that's powerful enough
to run the server and perform the tasks the server needs to perform.
There are different types of servers: web servers host web sites, database servers host
databases full of data, file servers host files that users can upload and download, game
servers host games that users can connect to and play with each other, a print server
hosts printing services that manage print jobs and a network of printers, and there are
many others.
A client
can refer to a machine, or it can refer to an application. Right now your computer is
connected to a local network, and is
therefore a client machine.
If you're also using your smart phone or tablet, you're probably also connected
to a local network or your carrier's network
(your phone service provider's network), so they're also clients.
Additionally, any software program that
allows your client machine to request information from a server, receives the
returned results, and then presents those results in a human-readable format is also
a client (client software, to be more precise). Your web browser is a client, for
example: You use the web browser to request web pages, which are then rendered
in the browser window for you to see and interact with. If you run an email program
on your computer such as Thunderbird or Outlook, you're using an email client.
An FTP client is a piece of software (such as WS-FTP, Core FTP, AnyClient, FileZilla,
etc) that allows you to connect to a server so you can upload and download
files. Think of any program on your computer, smart phone, tablet or other device
that allows you to access shared resources on a server out there somewhere
on the Internet: that's a client program!
Web Applications
How does client-server architecture apply to a course in web development?
Some of the technologies used to develop these applications are
server-side technologies, and others are
client-side technologies.
Server-side technologies, such as PHP, Perl, and MySQL perform their processing
on the server. Client-side technologies, such as HTML, CSS, and JavaScript
perform their processing on the client.
Examples of technologies used in web development:
Client-side:
HTML: defines the structure and content of a
web page; is rendered on the client machine.
CSS: defines the layout and style of an HTML
document; is rendered on the client machine.
JavaScript: a client-side scripting language that
provides interactivity in a web page; is compiled and run
on the client machine.
Server-side:
JavaScript: yes, JavaScript is a client-side technology,
but you can also now code server-side Javascript using technologies
such as Node.js
PHP: a server-side scripting language that can process
data sent to the server from the client and provides
file/database access; is run on the server.
MySQL: a database server software that hosts
large amounts of data that can be manipulated and accessed
via SQL and other server technologies (e.g. PHP)
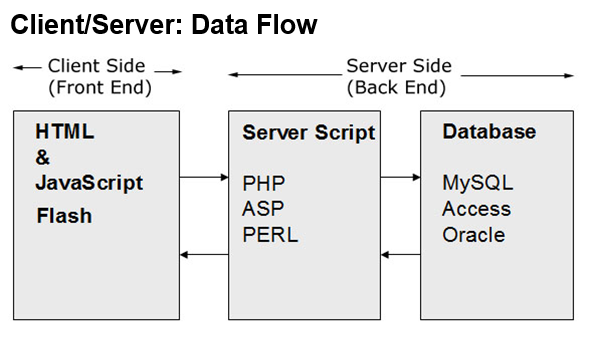
The data flow in a client-server network can be complex for interactive
web pages and for web applications. However, in these tutorials we start by
learning the fundamentals, which means we will be creating static
web pages (web pages with no interactivity, whose content doesn't change
unless the programmer changes it and uploads a new version). Static
pages have a very simple data flow on a web server:
Example of Client-Server Data Flow
In later tutorials, you'll learn how to use technologies such as
CSS, JavaScript, and PHP to create interactive and even dynamic pages
(pages whose content can change, or pages whose content is read from
sources like a database or JSON (JavaScript Object Notation)).
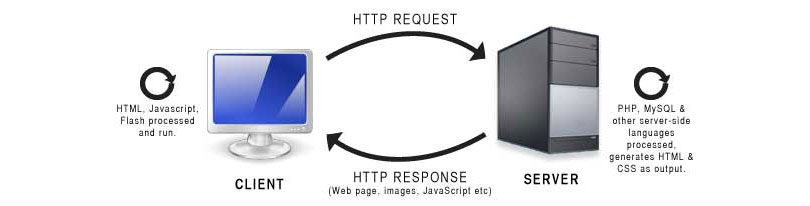
The Request/Response Model
The Request/Response
Model is how clients and servers communicate with each other.
The client sends requests to the server, the server then processes and
fulfills these requests, and then sends the response back to the client.
You click the link/bookmark or type the URL into your browser.
An HTTP Request object is created:.
HTTP stands for Hypertext Transfer Protocol. This is a system of
rules that allows "hypertext" to travel from one spot on the Internet
to another.
An HTTP request contains information about the URL you're
asking for, when the request is being made, where the request
is coming from, etc.
In this case, it requests the file wendisCats.html in the virtual
directory ~jollymor (this is an alias for a directory with
a much longer path!).
Your browser sends the Request object to the www-acad.sheridanc.on.ca
server.
The Request arrives at the server and is processed:
The server locates the wendisCats.html file in the
~jollymor/misc directory.
The server converts the file into a long
string of data.
A Response object is created:
The Response object contains the destination
address (the machine that made the original request)
and the string of data that contains the requested file.
The Response object also includes a response code
of 200 and the message "OK". This means that
the request was fulfilled successfully.
Other codes include 403 (forbidden - you're
not allowed to view this resource), 404 (resource
not found), 408 (request timeout - the client got tired of
waiting for the response), 500 (internal server error).
The server sends the response back to the machine that made
the request (your browser).
Your browser receives the Response object, opens it, and parses
the string of data:
It builds the HTML document
out of the received data.
If there are any references to files in the data, such
as an image or a .CSS file, new requests are made and sent
to the server for each one of those assets.
In this example, the file has a couple
of images, and it also references a javascript file
and a css file. New requests are made for each of those assets.
After the HTML document is created, the browser parses
the responses from any other asset requests: CSS files are
loaded and added to the HTML, images are added, etc.
The browser renders the complete HTML document so that
it's visible to the user.
Request/Response model: Shamelessly stolen
from http://demosthenes.info/blog/137/The-Client-Server-Model
If the request involves server-side processing, then the
process is a bit more complicated, as there are more steps
to be completed. For example, what happens when you log into
SLATE? You'll learn more about this process in the Web
Programming course in term 2.