Collections in Java (which used to be referred to as
"The Collections Framework") are utility objects that are used
in place of arrays, where arrays aren't enough.
For example, an array's size (length) is immutable in Java,
but the size of a collection object is not: a collection
object can grow or shrink without having to copy the
array contents into a new array. Collections can also be
more efficient for certain tasks than arrays, because there
are many different kinds of collections that are optimized
for specific tasks.
Generics (Parameterized Types)
In Java, Collections are parameterized
types. This means that you define collections for
specific objects (much like you define an array to hold only
integers or only Strings). Parameterized types make your collections
more modular and more cohesive (dedicated specifically to one specific
kind of object instead of several types of objects).
Before working with collections, it's important to understand
Generics and Parameterized Types.
Generics allow you to parameterize types when using or creating
classes and interfaces. In order to understand what this means, let's
review some terms from introductory lessons and define some new ones:
primitive type: a regular data type like int, float,
double, char, boolean, etc.
reference type: a data type that is a class type or interface type,
not a primitive type, such as String, Robot, Pos, ThreeD, Comparable,
or TextField
concrete type: an actual type/class; for example, if Circle and
Employee are classes, they they are concrete types
generic type (or formal generic type): a class that has a placeholder
with a type parameter e.g. Comparable<T> contains the type parameter T.
The type parameter T should be replaced with a concrete type such as Circle or
Employee.
type parameter: the generic type placeholder, e.g. in Comparable<T>, the
type parameter is T
type argument: the concrete type that replaces the generic, e.g. in
Comparable<Circle>, the type argument is Circle
parameterized type: when you instantiate a generic type using a concrete type
parameter, e.g. Comparable<Circle>: this is a parameterized type where the
generic parameter <T> was replaced with the type argument <Circle>
In the Java documentation it is stated, "To reference the generic
Box class from within your code, you must perform a generic type
invocation, which replaces T with some concrete value, such as
Integer: Box<Integer> integerBox;
You can think of a generic type invocation as being similar to an
ordinary method invocation, but instead of passing an argument to
a method, you are passing a type argument -- Integer in this case --
to the Box class itself."
The last sentence is helpful towards understanding how
generics works: When you parameterize a type, imagine you
are invoking a method where <T> shows you where you must
pass the name of the class/type you want to use, and replacing
<T> with a concrete type is passing that class/type name
to the method.
Why Do We Use Generics and Parameterized Types?
The main purpose of using generics and parameterized types is that it allows
you to create classes and interfaces that can be used with
a variety of different kinds of objects. For example, the
Comparable<T>
interface can work with any kind of object belonging to
class <T>. This allows you to use the Arrays.sort() method
on an array of a specific object. For example, if you have an
array of Circle objects, if your Circle class implements
Comparable<Circle> (and therefore overrides compareTo(Circle)),
then you can pass an array of Circle objects into Arrays.sort()
and it will sort those objects.
You will find many classes and interfaces in Java and Java
frameworks that use parameterzed types, so that those classes
and interfaces can work with any kind of class/object, even
classes that haven't been written, yet!
An advantage of Generics and Parameterized Types is that your compiler will capture
certain errors that might instead occur at run-time. To understand this,
let's look at an example using ArrayList<E>, which is one of the Java
Collections objects: an ArrayList is like a regular array, but it
contains only objects and the size/length is mutable (allowed to change).
In our first example, I'll use ArrayList without a concrete type to
replace the generic type <E>:
ArrayList<Shape> list = new ArrayList<Shape>();
list.add(new Circle());
list.add(new Cylinder());
list.add(new Scanner(System.in));
for (Object o : list) {
Circle c = (Circle)o;
System.out.println(c.getArea());
}
When you don't specify a concrete type for the type parameter <E>,
the Java list objects store only objects of type
Object. Recall that a variable/element of type
Object can receive any object, because Object is the parent of all
Classes in Java.
Therefore, everything you store in the list ArrayList
is automatically cast into an Object
type, so when you want to access the list elements, you'll need to cast them
back into Circle objects, as we see inside the for-each loop
on line 6.
The code in this example will throw a run time exception on line 6
for the 3rd element in the ArrayList, because Scanner is not a
Circle.
It's better to be notified of these kinds of errors during compile time
instead of compiling and deploying your program only to have it
crash later at some unknown time. Then you can fix the error
while you're still developing your application, instead of later.
ArrayList is actually defined as ArrayList<E>: <E>
is a type parameter for the ArrayList's element type. You should replace <E>
with a concrete type: the name of the class you want ArrayList to
contain instances of.
For example, we can define the ArrayList as a parameterized type for
Circles (and children of Circle) using the statement:
ArrayList<Circle> list = new ArrayList<Circle>();
Using a parameterized type for ArrayList, the following code will
now give us a compile error on line 4:
ArrayList<Circle> list = new ArrayList<Circle>();
list.add(new Circle());
list.add(new Cylinder());
list.add(new Scanner(System.in));
for (Circle c : list) {
// Circle c = (Circle)o; this line is no longer needed
System.out.println(c.getArea());
}
The compile error will indicate that we can't place a Scanner into
a list that is defined to contain Circle objects. The objects
stored in the list must be of the same type as (or children of)
the type argument. This is much
better and easier to fix instead of having to deal with a
runtime error later.
Notice that Line 6 inside the for-each loop has been commented out:
Since we've defined the ArrayList to contain Circle objects
(by using the concrete type Circle instead of the
generic type E), it knows that it
will only contain Circle objects or children of Circle.
Objects stored in the list are stored as
Circle objects, not Object objects,
and we don't have to cast them. This then, is a second advantage
to using generics: it makes casting unnecessary.
A third advantage of using generics and parameterized types
is that it allows you to
create code that is more consistent and allows you to create
code and algorithms that will work on any kind of collection.
In fact, you'll see this already in place in the Collections
classes and interfaces that are already part of Java.
For example, you can use an Iterator to iterate through any
kind of List collection, no matter which List type it is
and no matter what kind of objects the List contains.
Another example: you could write a method that sorts any kind of
List object, whether it be an ArrayList, LinkedList, or some
other kind of List. That kind of technique is beyond the
scope of this tutorial at the moment, but perhaps it will
be added some day.
As you learn about the various collection objects in Java,
you'll be using parameterized types.
Collections Overview
The collections framework contains many classes
and interfaces that not only model the collection
objects themeselves, but also provide tools that
allow you to work with collections, performing
many common tasks in the most efficient way.
What's in Java's Collections?
The Collections Framework includes:
A set of interfaces that act
as frameworks or templates for various collection classes.
These help provide a consistent implementation between the
different kinds of collections. For example, all collections
have a size() method that returns the number of objects
in the collection, and you can use that method no matter what kind
of collection you're working with.
Various abstract classes that contain common
implementations for various categories of collection
classes.
Concrete classes that model different types
of collections, such as collections that only contain
unique items, collections where items can be sorted or processed
in different ways, collections where elements are identified by
numeric indexes, collections where elements are identified by
unique objects, and so on.
Iterators are also represented by a
set of interfaces. Iterators allow you to easily traverse
or loop through a collection in a very efficient way (much
more efficient than just using a counted for-loop).
There are different types of containers in the
collections framework:
Lists: used for storing a collection of objects
that can be accessed by a numeric index, and may be
stored in a certain order.
Sets: used for storing a collection of unique objects
that are stored in no particular order and can't be accessed
by a specific index (you might access them only by traversing/iterating
the collection).
Maps: used for storing a collection of objects as
key-value pairs, where a key is a unique index to a specific
object in the collection.
Maps can contain duplicate values, but keys must be unique.
Collections Interfaces
There are a set of interfaces that help to provide some
consistent behaviour between the different kinds of collections.
For example, collections that have numeric indexes all have
a get() method that accepts an index and returns an object at
that index; collections that use non-numeric indexes have a next()
method to move to the next object, or a getValue(key) method
to retrieve the object stored with a specific key.
Having these common sets of behaviours mean that it's easy to
write re-usable code that processes collections objects,
no matter what type of collection you're dealing with.
Here are some of the more common interfaces we'll be
looking at:
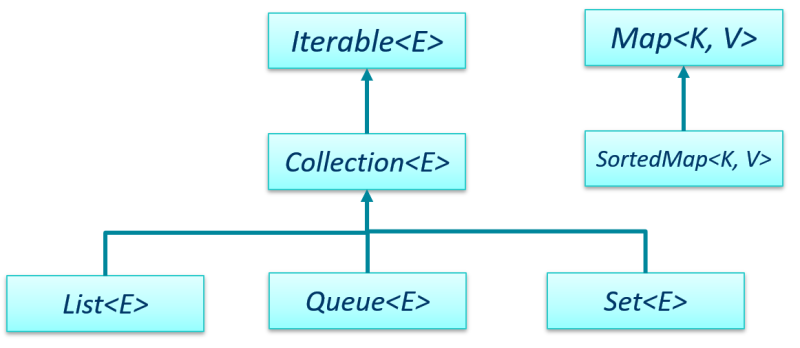
A hierarchy of some of the collections interfaces.
Collection<E> is the main interface that
contains common methods used by all
collection classes (except Maps).
Some common methods in this interface are add(), clear()
(emtpy the collection of all its objects),
size(), contains() (returns true if a specific object is
in the collection), etc.
Most classes in the collections framework implement
Collection<E>, so all those classes have those methods
available. Each class might implement the methods differently;
for example, the add() method for an ArrayList<E> adds
the object to the end of the list, but add() for a
LinkedList<E> adds the object and updates the relevant
link in the previous object.
An interface that's a child interface of Collection<E>,
is used for sequential collections that store lists of
objects, where the list allows for duplicate objects.
Classes that implement List allow access to list elements by
their indexes, much like a regular array. For example, you
can add an object at a specific index, retrieve an object at a
specific index, or even search for objects and retrieve their
numerical indexes.
Concrete classes implementing List include LinkedList<E>,
Vector<E>, and ArrayList<E>.
The Set<E> interface extends Collection<E>, so it
inherits the common methods in Collection<E>. A Set is a
Collection that is not allowed to contain duplicate elements.
If you've ever studied sets in a math class, this
concept should already be somewhat familiar. For example, a
Set can represent a set of playing cards in a player's hand,
or a group of students a teacher has in their programming class.
In both examples, duplicates would not exist: there is only
one of each playing card: you couldn't
have the same card twice in your hand. Similarly, there is
only one of each student: you couldn't have a student appear twice
in the class list.
Concrete classes implementing Set include HashSet<E>,
LinkedHashSet<E>, and TreeSet<E>.
A map is a structure that maps keys to values. You might
have used a JSON object in JavaScript, an associative array
in PHP, or a dictionary in Python: these are similar to Maps.
A map's elements consist of a unique key
or index that is mapped to or associated with a specific
object (the value). A key can only map to one
value/object. Keys can be integers (as objects), Strings, Objects, or
anything else, as long as they're all unique.
You might notice that instead of <E>, Map uses <K, V>. The K
is a generic placeholder for the key type and the V is the generic
placeholder for the value type. For example, if you wanted to
make a Map<K, V> where they key was a String and the value
was an Inventory object, you'd use Map<String, Inventory>.
Element values in a Map can be duplicated, unlike Sets;
however, keys must be unique - duplicate keys are not permitted.
The Map interface contains all of the common methods used
in various concrete map collection classes, such as
clear() (removes all mappings), containsKey() (finds an
entry with a specific key), containsValue() (finds an entry with
a specific value), put() (adds an entry), and get() (retrieves
an entry).
Concrete classes implementing Map include HashMap<K, V>,
LinkedHashMap<K, V>, and TreeMap<K, V>.
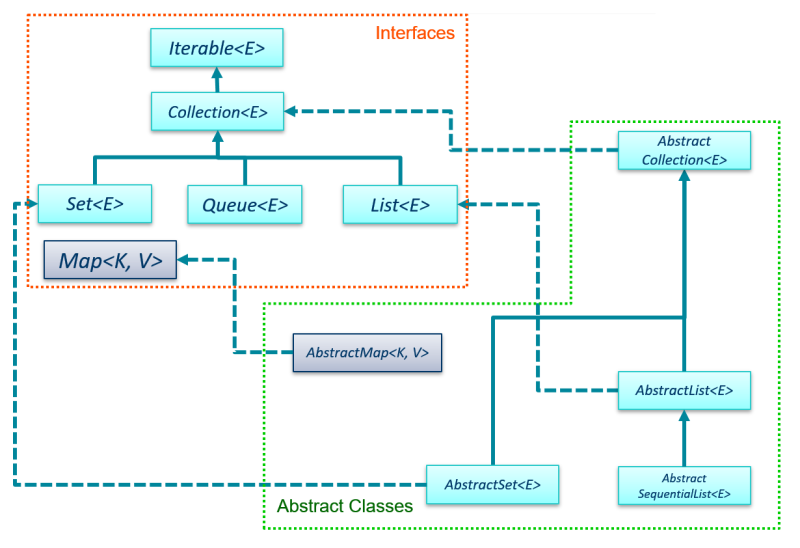
There are a few other interfaces in the diagram above,
and we'll look at those in detail later.
Abstract Classes
There are also some abstract classes that make up
the collections framework. These classes implement
various interfaces and implement the methods defined in
those interfaces. This makes it easier
to create concrete classes: The concrete classes such
as ArrayList<E> and HashSet<E> can be extended from
abstract classes that already override methods defined
in their respective interfaces.
Some common abstract classes in the collections
framework
AbstractCollection<E> implements the Collection
interface, so it has implementations of the abstract methods
defined in Collection.
AbstractSet<E> implements the Set interface,
so it has implementations of the abstract methods defined in
Set
AbstractList<E> implements the List interface,
so it has implementations of the abstract methods defined
in List.
AbstractSequentialList<E> is a child of
AbstractList, and was created to provide "sequential access" to
objects stored in a list.
In other words, it contains methods common to classes that might
not allow direct access to collection elements.
AbstractMap<K, V> implements the Map interface,
so it has implementations of the abstract methods defined
in Map.
Why is it important to know the abstract classes? When you
read the API documentation for a particular collections class,
you'll have to remember to also check and see what methods
are inherited from parent classes!
Collections: Lists
Lists are used for storing lists of objects, much like a
regular array. Lists use numeric indexes to provide
direct access (otherwise known as
random access) to elements/objects in the
list. Lists can be sorted in a specific order and also
allow for duplicate elements/objects.
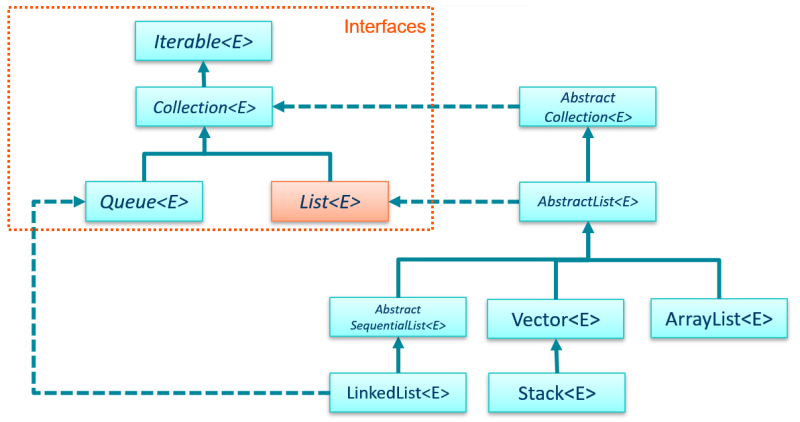
Some of the List classes.
Before getting into the concrete list classes, you might
be interested in one other interface that's often used
with lists: the
Queue<E> Interface.
A queue is a special kind of list that store objects while
they wait to be processed. A Queue<E> is a "first in, first out"
structure: The first item into the queue is the first item to
be processed, and the last item into the queue is the last item
to be processed. This is just like a line-up: if you line up
at the Tim Horton's, you have a spot in the queue. The first
person in the queue is served, then the person after that is
served, etc.
The Queue<E> interface is a child of Collection<E>.
It contains additional functionality specific to queues.
For example, adding an item to a queue puts it at the end of
the list, and getting an item from a queue takes an item from
the beginning of the list.
In programming, you might create a queue to process print jobs
being sent to a printer, or packets being sent to a router.
The LinkedList<E> class mentioned below
implements Queue<E> (through the child interface
of Queue<E> called Deque<E>) so you can use a
LinkedList<E> object to program a queue structure.
A concrete class you can instantiate when you want a list of
objects stored in a dynamic array (an array that can grow and
shrink to accommodate the objects placed inside it).
An ArrayList<E> is the most efficient collection when it comes
to storing and accessing (i.e. reading) objects using
numerical indexes. If you're going to be manipulating the list
objects a lot, it's better to use a LinkedList<E>, instead.
A Vector is very similar to an ArrayList<E>. It's dynamic,
but a vector is synchronized, unlike an ArrayList.
"Synchronization" is beyond the scope of this course (if you're
somewhat familiar with threads, a vector is thread-safe, whereas
an ArrayList isn't). For now, all you need to worry about
is that a Vector is less efficient than an ArrayList,
so you should use an ArrayList until you learn more about
threads and synchronization.
Vectors are actually obsolete, and your editor might warn
you of this when you use it in a program. It's kept around
for backwards compatibility. But just for fun, here's some
code that uses a vector:
// create a vector with an initial capacity of 5
// and a capacity increment of 2 (size will increase
// by 2 whenever size becomes > capacity)
Vector<String> vector = new Vector(5, 2);
vector.add("cat");
vector.add("dog");
vector.add("fish");
vector.add("ferret");
vector.add("hamster");
vector.add("monkey");
System.out.println(vector.capacity()); // prints 7
System.out.println(vector.size()); // prints 6
System.out.println(vector.firstElement()); // cat
System.out.println(vector.lastElement()); // monkey
System.out.println(vector.get(3)); // ferret
A concrete class you can instantiate when you want a list of
objects stored in a dynamic array.
Each element in a linked list points to the next element
(in a doubley-linked each element points to both the next
element and the previous element).
If you need to add elements to both the beginning and end of a list,
the LinkedList<E> is easier as it contains methods for
this purpose.
Manipulating elements is also much faster in a LinkedList<E>,
so if you're doing a lot of adding/removing/editing of
objects, you should use a LinkedList<E>.
If you're storing and reading objects only, it's more
efficient to use an ArrayList<E>.
Linked List Example:
// creates an empty linked list
LinkedList<String> links = new LinkedList();
links.add("cat");
links.add("dog");
links.add("fish");
links.addFirst("ferret"); // ferret, cat, dog, fish
links.addLast("hamster"); // ferret, cat, dog, fish, hamster
for (String s : links) {
System.out.println(s);
}
System.out.println("First: " + links.getFirst()); // ferret
System.out.println("Last: " + links.getLast()); // hamster
System.out.println(links.get(3)); // fish
System.out.println("Bye: " + links.remove()); // removes ferret!
System.out.println();
for (String s : links) { // cat dog fish hamster
System.out.println(s);
}
links.add(1, "monkey"); // monkey between cat and dog
links.add("llama");
links.add("dog"); // adding dog twice!
links.add("ostrich");
links.add("platypus");
links.removeFirstOccurrence("dog");
// see also removeLastOccurrence(), removeFirst(), removeLast()
System.out.println();
for (String s : links) {
// cat monkey fish hamster llama dog ostrich platypus
System.out.println(s);
}
A stack is a "last in, first out" data structure: the
last item added to the stack (the top) is the first item
out or processed. New elements are added top (beginning)
of the stack. The items at the bottom (end) of the stack were
items added earlier, and are last to come out.
Example: if you go to some restaurant buffets, they have
a stack of plates. A customer comes along and picks up the
top plate off the stack, which was the last plate added to
the stack (e.g by a staff member).
It's someone's job to keep the plates from running out:
the first plate they put onto the stack is the last plate
taken off by a customer.
The Stack<E> class contains special methods such
as push() (put an item on top of the stack) and pop()
(take an item off the top of the stack).
Stacks are used in programming to keep track of where
the program flow is: when you get an error, you get a
"stack trace" which shows you a sort of bread crumb trail
of the various methods the program was executing when the
error occurred.
// read the API, there are better ways to make a Stack
// default stack is empty, no other constructor available
Stack<String> stack = new Stack();
stack.push("cat");
stack.push("dog");
stack.push("fish");
stack.push("hamster");
for (String s : stack)
System.out.println(s);
// the item on the end/bottom is actually the TOP of the stack
// think about the stack of plates!
// hamster <-- top
// fish
// dog
// cat <-- bottom
System.out.println("Peek: " + stack.peek()); // look at top item
System.out.println("Popped " + stack.pop()); // removes top item
System.out.println();
for (String s : stack)
System.out.println(s);
Collections: Sets
Sets are collections of elements/objects that don't have
numeric indexes, so you don't access them directly the same
way you do with lists. Additionally, a Set is not allowed
to contain duplicate values. Think of a set like a poker hand
with 5 cards: you wouldn't have two of the same card in your
hand - you'd have 5 unique cards.
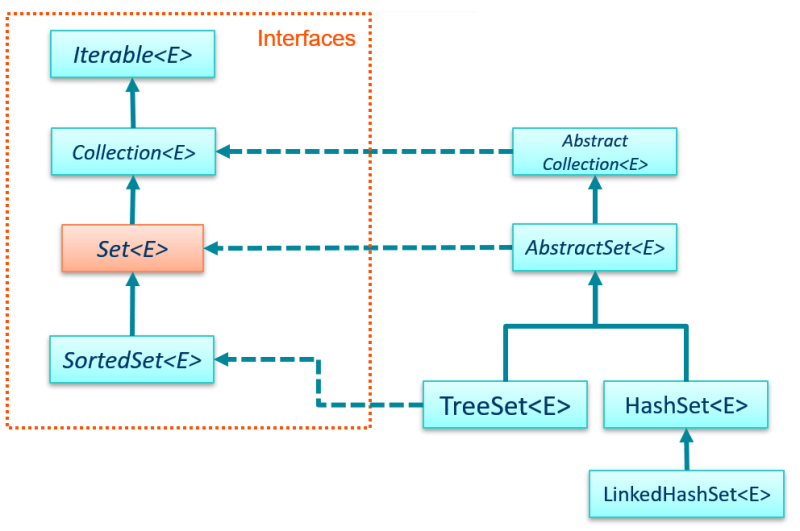
Some of the Set classes and interfaces.
Sets resemble the same sets you probably learned about in an
intermediate math course. A set contains unique objects,
and you can take multiple sets and find the intersection
of those sets using a method like retainAll().
Sets don't use indexing, because there is no guaranteed
order to a normal set; you can't just retrieve a Set
element directly like you can with a list.
To process a Set, you need to use a for-each loop
or an Iterator.
Use a concrete set class when you want to maintain a list
of objects where you need to ensure there are no duplicates.
For example, you could make a Quiz set which contains a set
of unique questions, so you don't give the same question
twice.
A HashSet<E> is the most efficient of the Sets.
You can specify a load factor when you create
a HashSet<E>, which determines how much the
HashSet<E> should expand when a new element is added
after the maximum capacity is reached.
HashSet<E> elements are stored in no particular order.
When you add objects to the set and then display them later,
you'll likely notice that they don't appear in the
same order in which you added them.
HashSet<String> set = new HashSet<>();
set.add("Bird");
set.add("Cat");
set.add("Dog");
set.add("Fish");
set.add("Hamster");
set.add("Monkey");
System.out.println(set);
for (String s: set) {
System.out.println(s);
}
Output:
[Bird, Cat, Monkey, Fish, Dog, Hamster]
Bird
Cat
Monkey
Fish
Dog
Hamster
LinkedHashSet<E> is a child of HashSet<E>, and allows
you to create a HashSet<E> that works more like a
LinkedList<E>, so you can impose some sort of ordering on
the set elements.
When you add items to a LinkedHashSet<E> and then display
them, the items will be displayed in the order in which you
added them.
If you want to change the order of the items in a
HashSet<E> or a LinkedHashSet<E>, use a TreeSet<E>.
TreeSet<E> implements the
SortedSet<E> interface, which is a child
of the Set<E> interface discussed earlier.
Collections: Maps
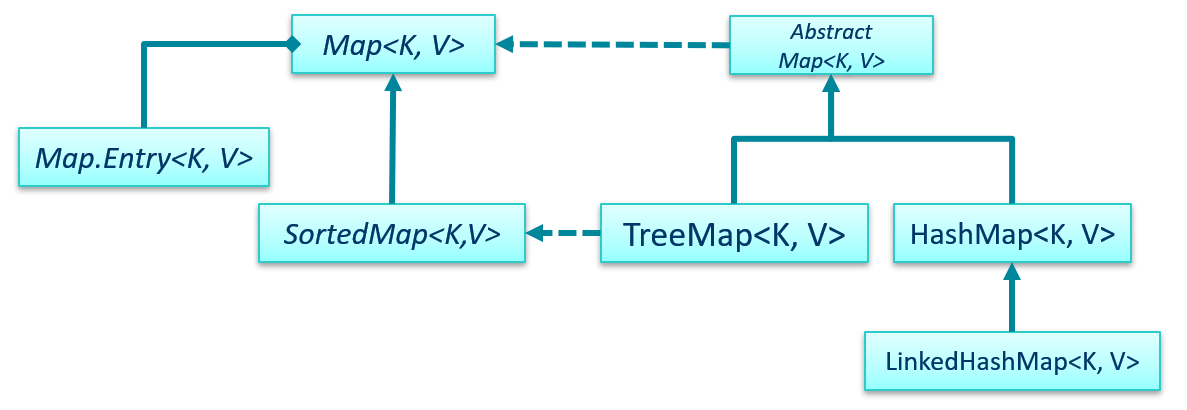
Some of the Map classes and interfaces.
Maps are used for storing collections of objects that can be
easily retrieved with a specific key.
The key can be any class type (so if you want a Map with
integer keys, you'd have to use Integer, for example). Keys
must be unique.
Each key is associated with an element value. These are called
key-value pairs. The values don't have to be
unique - you can store duplicate objects mapped to different
keys.
A Map's elements are usually called entries,
and can be modeled by the nested interface
Map.Entry<K, V>.
Map.Entry<K, V> is owned by the Map<K, V> interface.
In fact, Map<K, V> contains a method entrySet() that returns
a Set<E>! This Set object contains the set of
Map.Entry<K, V> objects stored in the map.
You might use a Map to store a collection of
configuration options where the key is the String name of the
configuration option (e.g. "backgroundColour" or "fontSize")
and the value is the user's preferred settings for this
option. Or you could store information about managers
at each store in a chain: They key could be a Store
object for a specific store, and the value could be the
Employee object for the manager of that store.
A child of AbstractMap<K, V>, HashMap<K, V> is a
concrete Map<K, V> class that's very efficient when it comes
to adding, removing, and searching for map elements.
Like a HashSet<K, V>, entries in a HashMap<K, V> are
not in any particular order. If you need an ordered HashMap<K, V>,
use a LinkedHashMap<K, V> or a TreeMap<K, V>.
Example using HashMap:
// initial capacity of 10 and default load factor of .75
HashMap<String, Shape> shapes = new HashMap(10);
shapes.put("defaultCircle", new Circle());
shapes.put("defaultCylinder", new Cylinder());
shapes.put("defaultSphere", new Sphere());
shapes.put("smallCircle", new Circle(1.5));
shapes.put("smallSphere", new Sphere(1.5));
System.out.println(shapes.size());
// Map.Entry<K, V> models one entry/element (a key-value pair)
// in the hashmap.
// hashmap's entrySet() method returns a SET of Map.Entry objects
// where each Map.Entry models one key/value pair stored in the
// hashmap.
// So this loop says "For each key-value pair in the hashmap..."
for (Map.Entry<String, Shape> element : shapes.entrySet()) {
// Map.Entry<K, V> has a getKey() method: returns the key as <K>
// Map.Entry<K, V> also has getValue() method: returns the value as <V>
// in our example, getKey() returns <String> and getValue()
// returns <Shape>
System.out.printf("Key: %s%nShape: %s%n", element.getKey(),
element.getValue());
// note implied call to shape's toString() when you print getValue()
}
This example is interesting, as it shows how different
a Map collection really is.
Map.entrySet() returns a Set<E> where
each set element is a Map.Entry<K, V>.
In other words, the set returned by entrySet()
is a Set<Map.Entry<K, V>> !
Map.Entry<K, V> contains a getKey() method,
which returns the entry's key/index as type <K>,
and a getValue() method, which returns the entry's
value as type <V>. So in our example, the
key is a string and the value is a shape,
so the entries are Map.Entry<String, Shape>
and therefore, getKey() returns String and getValue()
returns Shape.
LinkedHashMap<K, V> is a child of HashMap<K, V>: it's a HashMap<K, V> where
items are stored either in insertion order (the order
they were added) or access order (the order in which they
were last accessed).
Iterators allow you to iterate through various types collections.
Iterators are a very common design pattern used to visit
elements in any data structure in such a way that it doesn't
matter how the data sits in the collection, you can still
iterate through all of the elements in some way.
The Collection<E> interface extends the
Iterable<E>
Interface, which makes any Collection<E> object iterable.
To iterate through a collection, you obtain its
Iterator<E> using the iterator()
method that's defined in the Iterable<E> interface
(so therefore it's inherited by all the Collection classes).
An Iterator<E> has methods like next(), hasNext(), and
remove().
Iterators make it easy to write re-usable code that can
traverse through any type of collection, regardless of the type of
collection or the type of objects the collection contains.
The List<E> interface contains the listIterator() method,
which retrieves a
ListIterator<E>,
a more specific kind of Iterator made for List<E> collections.
Where an Iterator<E> can only move forward through
a collection and not add/edit elements, a ListIterator<E> can move
forwards and backwards through a collection, and provides methods for
adding or editing the objects in the list.
Note that iterators all have a remove() method for removing
the current element from the list, but it should be used with
great care.
Iterator Examples:
LinkedList<String> list = new LinkedList();
list.add("cat");
list.add("dog");
list.add("fish");
list.addFirst("ferret");
list.addLast("hamster");
Iterator<String> iterFwd = list.iterator();
while (iterFwd.hasNext()) {
System.out.println(iterFwd.next());
}
System.out.println();
ListIterator<String> iterBack = list.listIterator(list.size());
while (iterBack.hasPrevious()) {
System.out.println(iterBack.previous());
}
The biggest benefit of using Iterators is that they are able to
traverse or loop through any kind of collection. The example above
would also work with an ArrayList, instead of a LinkedList:
ArrayList<String> list = new ArrayList<String>();
list.add("cat");
list.add("dog");
list.add("fish");
list.add(0, "ferret");
list.add("hamster");
// exact same code as previous example:
Iterator<String> iterFwd = list.iterator();
while (iterFwd.hasNext()) {
System.out.println(iterFwd.next());
}
System.out.println();
ListIterator<String> iterBack = list.listIterator(list.size());
while (iterBack.hasPrevious()) {
System.out.println(iterBack.previous());
}
The code that uses the Iterator in the previous two examples will
even work with a set:
HashSet<String> list = new HashSet<>();
list.add("cat");
list.add("dog");
list.add("fish");
list.add("ferret");
list.add("hamster");
// exact same code as previous example:
Iterator<String> iterFwd = list.iterator();
while (iterFwd.hasNext()) {
System.out.println(iterFwd.next());
}
Note that the ListIterator part of the code won't work because
ListIterators are only available to Lists, not to Sets or Maps.
The For-Each Loop
You should already be familiar with the for-each loop:
for (String s : list) {
System.out.println(s)
}
When you're reading (not modifying) a collection, you can
use the for-each loop, because it also works in a consistent way
for various kinds of collections.
Furthermore, if you're going to do nested iteration with collections,
it's actually better to use a for-each loop
because it's easier for programmers to unknowingly encounter logic
errors when using Iterators in some nested loops
(for more information see Geeks for Geeks: Iterator vs. Foreach in Java).